
The NoSQL databases implement various techniques to meet the need for even faster access to (big) data: the asynchronous API is one of them.
Let’s be down to the earth: to store or retrieve information, the client application exchanges data with the NoSQL database through a roundtrip made of 3 main stages:
- command sending / query
- command processing / query within the NoSQL database
- sending back of the response
1. How it works with synchronous API
From the client application perspective, the simplest way is to call synchronous APIs. The synchronous API imposes only one call at a time. In other words, the client application will be paused until he got the answer.
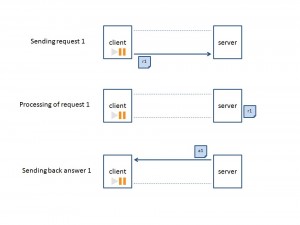
After receiving the answer, the client is freed and can initiate a new call.
2. How it works with asynchronous API
Another way to make the data exchange is to call the asynchronous API. When calling the asynchronous API, the client application resumes without waiting for the results. The client application can call the asynchronous API whereas the previous calls are not completed.
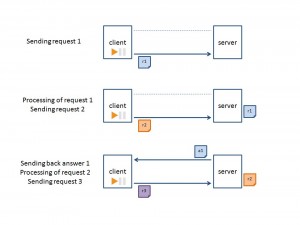
Using a single TCP connection:
- a set of data can be transmitted in one shot, for sending
- sending and receiving can occur simultaneously
- a set of data can be transmitted in one shot, for reception
In other words, sending, processing and answering can be performed simultaneously. Considering these 3 main steps, 3 asynchronous calls are going on simultaneously on the same TCP connection.
Besides, asynchronous API goes through the implementation of callback functions for dealing with the multi-requests approach. This adds a small layer of complexity in the development of the client application, in exchange of a noticeable impact in terms of performance.
3. All the stages of a round trip
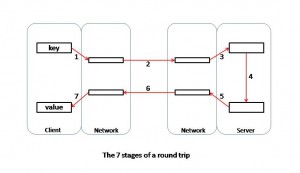
Between a request and its response, the data is copied 7 times:
- copy the request from the client application to the sending buffer,
- sends the request from the sending buffer to the receiving buffer,
- copy the request from the receiving buffer to the server application,
- calculate the response inside the server application,
- copy the response from the server application to the sending buffer,
- sends the response from the sending buffer to the receiving buffer,
- copy the response from the receiving buffer to the client application,
With asynchronous API, data are placed on all these steps. So they take place at the same time, as in a factory production line. The result is a 7 times higher throughput.
4. Pipelining
Pipelining also increases performances but for another reason.
This time, it is necessary to make the analogy with a transport shuttle. Since the journey takes time, to make the best use of the means of transport, it is preferable to fill up the shuttle before letting it go. Otherwise, the shuttle is wasting part of its capacity, reducing the volume of passengers.
The network equivalent consists in filling the messages to their optimal size. To do that:
- group the requests instead of sending them one by one
- group the answers instead of sending them one by one
This way you will get an optimal throughput of data at each roundtrip.
Combining asynchronous API and pipelining will produce a 10 times higher throughput.
Conclusion
The asynchronous API requires a few additional developments with the callback function(s); however it mechanically improves performance by a factor between 7 and 10 depending on the combined implementation of the pipelining technique.
Mixing synchronous and asynchronous API, UDP and TCP connections, can lead to even better performance under some conditions.
Index64 implements synchronous API and asynchronous API with pipelining. The resulting thoughput is 8 millions operations per second.